
Types of Machine Learning Algorithms

In the last couple of years, concepts like machine learning, artificial intelligence, deep learning, NLP (Natural language processing), neural networks, and many others have become buzzwords. They have been gaining popularity as more and more people keep searching for them on the Internet.
Also, there has been a significant increase in the search volume of these terms.
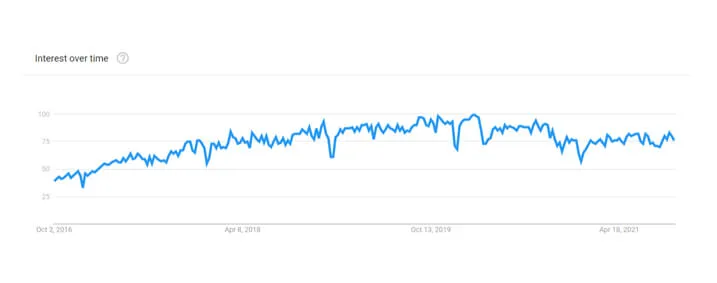
A global number of searches for term machine learning in the last 5 years.
People are using the mentioned terms more and more in their everyday speech, without even understanding them (or at least with partial understanding of what these terms stand for). This is how we came up with an idea to start a series of blogs about Machine Learning whose aim is to demystify and explain some of the most frequently used approaches, both on a high level of abstraction and a lower level with examples of implementation of code in Python.
What is Machine Learning?
For starters, it is necessary to define what exactly is Machine Learning. Machine Learning focuses on the research of computer algorithms with the aim to identify patterns in data. Based on the identified patterns a Machine Learning model will be created which will be used for predicting the future behavior of the system or recognizing the identified patterns in new, previously unknown input examples.
People often recognize patterns in smaller data sets themselves, but when the amount of data increases and the level of complexity increases, various algorithms of Machine Learning help in finding aforementioned patterns.
Machine Learning is currently implemented in various fields and some of them include:
- Speech Recognition
- Object recognition in images
- E-mail filtering and many others
The algorithms of Machine Learning can be divided into three big sub-groups, and these include:
- Algorithms of Supervised Machine Learning
- Algorithms of Unsupervised Machine Learning and
- Reinforcement learning
In the rest of the article, we will describe and explain each of these groups, as well as some of the algorithms and we will provide examples of the problems they solve.
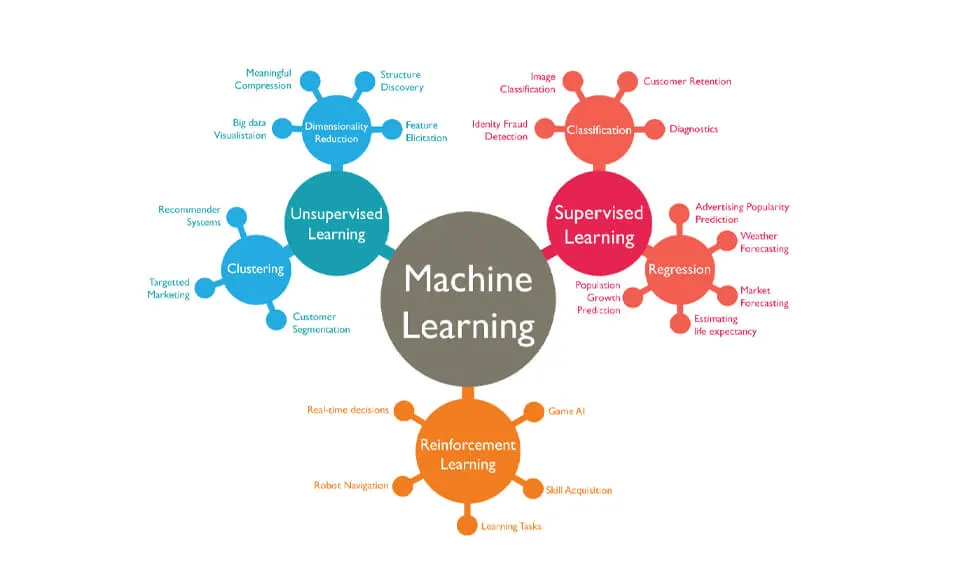
A graphic categorization of Machine Learning algorithms
Supervised Machine Learning
Supervised Machine Learning represents one of the most frequently used techniques of traditional Machine Learning. This group of Machine Learning algorithms is characterized by the presence of dependent and independent variables.
Independent variables are also known as attributes, while dependent variables are also known as target variables. The purpose of these algorithms is to understand the relation and recognize patterns of independent variables based on which the prediction of dependent variables is conducted.
The algorithms of Machine Learning require causal links between attributes (independent variables) and target variables (dependent variables) which are presented using a mathematical formula. The quality of this trained model is usually quantified by the level of accuracy which represents the quotient of the number of instances for which the target variable is accurately predicted and the total number of instances that have been subjected to prediction. The level of accuracy is presented in percentage, and it depends on the algorithm itself, the quality of the sample which is subjected to prediction. The process of model training lasts until a certain level of accuracy is achieved with the trained data set. The trained model is the basis used for future predictions of target variables for previously unknown cases.
Supervised Machine Learning is based on the premise that algorithms will train the model with use of multiple examples. To make this process successful, it is necessary to fulfill some preconditions.
- It is necessary to have a large number of examples for model training. The specific number of examples for training models depends on the complexity of the problem itself which is being solved and it is usually expressed in thousands. If the model archives a high level of accuracy with a trained data set, a low level of accuracy with the tested data set, it is necessary to create a few more training examples.
- Trained data set must contain various combinations of attributes and target variables to make the model robust. Different techniques are applied to improve input data sets and better adapt to the problem that needs to be solved. Some of the most frequently used are removing extreme values, removing unknown values, reduction of dimensionality, adding noise and the synthesis of new samples using SMOTE algorithm.
- The data used for model training must be meaningful and have a structure so that the model could recognize complex connections and patterns inside of them.
- It is important to pay attention to the validity of the trained model. If the rules according to which assumptions are made are subjected to frequent changes, it is necessary to train models again and consider newly identified rules.
Some of the examples of supervised Machine Learning include:
- Linear regression
- Decision trees
- k-Nearest neighbors
- Neural networks
Areas, where the algorithms of supervised Machine Learning are implemented, are various. Linear regression can be used to predict salaries based on years of working experience. Decision Trees are suitable for predictions whether a buyer would like a certain product or not based on the similarities between that buyer and other buyers. kNN is implemented for various types of classifications when the number of classes is known in advance. Neural networks are the most robust and are used for the prediction of the prices of the stock market shares based on the historical overview of prices, object classification in images, the automatic suggestion of the following word in the sentence, and many other things.
Unsupervised Machine Learning
Unsupervised Machine Learning can be defined as a process of introducing some form of structure for unstructured data based on recognized patterns in data.
Assuming that the data is not randomly generated, meaningful patterns, which algorithms of unsupervised learning will try to detect, will exist. It is also important to mention that unsupervised learning adds the structure by looking for and adding new attributes based on recognized patterns.
Only recently has the true potential of the algorithms of unsupervised learning been recognized. Some of the advantages of these algorithms, when compared to the traditional algorithms of supervised learning include the fact that unsupervised learning is less dependent on initial assumptions and the potential solution could converge in any dimension. In this way, the algorithms of unsupervised Machine Learning have a greater potential for detecting the hidden data patterns which have not been previously considered.
Some of the frequently used algorithms for creating models by implementing unsupervised learning include:
- Apriori
- K-means
- Principal component analysis
Currently, some areas where unsupervised learning is implemented include detection of a fraud, where K-means is suitable, the analysis of market baskets with algorithms for finding association rules such as apriori, and the reduction of dimensionality of data sets through PCA algorithm.
Reinforcement Learning
Reinforcement Learning is inspired by behavioral psychology and is based on the concept of rewarding and punishing the agent based on its behavior in a predefined dynamic surrounding.
At its core, the agents who independently make decisions are rewarded or punished based on the fact how much the decision they have made would be suitable for the given situation.
The quality of the decision made is calculated by using pre-defined sets of rules which are called heuristics. We could say that the agent uses the feedback on the performed activities to find out which sequences of actions are suitable in different scenarios so that the agent would reach the final goal.
There are two important characteristics of Reinforcement Learning:
- Exploitation rate
- Exploration rate
It is often necessary to find the right balance between the values of these two variables to train the model optimally.
If the level of exploitation rate is initially high, the agent can get stuck in local optimums, while a very high level of exploration rate leads to the cases where the agent has a bigger tendency to forget good actions and strive towards trying out new suboptimal actions.
Reinforcement learning consists of three important parts:
- A set of finite environment states
- A set of possible actions in each state
- A real-valued reward function
A set of finite environment states defines the environment where the agent is located, the set of possible actions defines which actions the agent can perform in certain situations while a real value reward function presents a predefined function for evaluating the actions which the agent chooses in a specific environment state.
Algorithms that are used include:
- Policy-based algorithms
- Value-based algorithms
Reinforcement learning has been mainly implemented in training agents which play games like chess, Pac-Man, Scrabble, and other similar board games. Besides gaming, reinforcement learning is applicable in areas like robotics, self-driving cars, chatbots and many others.
Currently, Google’s AlphaZero is dominant in games like go, shogi and chess and has outplayed a human a long time ago. It is an interesting fact that only 9 hours of training the AlphaZero program is enough to enable it to beat specialized chess programs like Stockfish.
The field of Machine Learning is continually developed and it can be implemented in many areas in everyday life. We are often not aware of how much different algorithms of Machine Learning are present, how much they help us make decisions and increase the quality of our lives.
In the following articles from this series of blogs about Machine Learning, we will dive deeper into the topics of supervised and unsupervised Machine Learning and provide examples of implementation of the most used algorithms in Python.
